MIT iQuHACK 2021 — Division Winner
Team QriKET: Ian Boraks; Amir Ebrahimi; Sehmilul Hoque; Aleks Siemenn; Tavin Turner
GitHub repository · Medium write-up
My role
I founded the QriKET team for MIT iQuHACK and pulled together a cross-disciplinary group to explore quantum algorithms + ML in a weekend-sized research sprint. As project lead, I kept us pointed at a question we could actually answer on the clock: when does a quantum distance routine buy you something measurable in a classification story?
My own hands-on work skewed toward evaluation and visualization—building the glue code that turned model outputs into plots and tables we could trust during judging. That included decision-boundary figures and truth-table style summaries that made our peak 96.6% abstract-game accuracy legible at a glance.
I also owned a lot of the “translation layer” between experimentation and narrative: making sure the final story matched the numbers, and that the numbers matched the implementation.
Introduction
We implemented nearest-centroid classification in two regimes: a fully classical baseline and a variant that uses quantum distance estimation to approximate inner products. The toy domain is chess board classification—given a mid-game snapshot, predict whether Black or White has the structural advantage—but the framing generalizes (rapid triage, lightweight scoring, anything where a centroid story is plausible).
We then “gameified” the comparison: humans, classical models, and quantum models compete head-to-head on held-out states.
Basic principles
Nearest centroid classification is a supervised recipe: learn centroids in feature space, then label points by proximity (here, Euclidean distance). The quantum path swaps the classical inner-product work for a quantum subroutine whose complexity scales differently—our write-up frames it as moving from O(n) toward O(log n) for the distance piece, with the usual caveats about constants, noise, and problem size.
We generated N random mid-game boards. 90% trained both models; 10% tested them. Each board maps to a 2D feature vector:
- x₁ = sum(Black piece values) / sum(White piece values)
- x₂ = max(Black “best capture” value) / max(White “best capture” value)
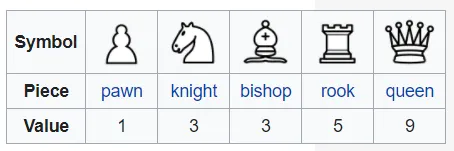
Piece values follow standard chess heuristics:
The best-move value is a simplified proxy: among legal moves, take the best immediate capture score; checkmate-flavored captures are capped with a large bonus (the original write-up used 40 for king capture). Labels indicate which side the model should classify as “ahead.”
Results — chess data
With N = 400 boards:
- Classical accuracy: 86.0%
- Quantum accuracy: 78%
Classical — training

Classical — testing

Quantum — training

Quantum — testing

Results — abstract game
We repeated the experiment on a more abstract feature space where the quantum model had more headroom. With N = 300:
- Classical accuracy: 73.3%
- Quantum accuracy: 96.6%
Classical — training

Classical — testing

Quantum — training

Quantum — testing

Interactive game
The demo lets a human compete against both trained models on five unseen states—same inputs, same scoring, instant feedback.

